
2025 年初,DeepSeek R1开源,如一颗重磅炸弹投入大模型领域,在全球范围内引发连锁反应:
-
逼着OpenAI急忙发布o3-mini、OpenAI CEO奥特曼承认OpenAI“站在了历史的错误一边”;
-
逼着另一个大模型头部玩家法国Mistral AI急忙推出其新一代生成应用Le Chat,同时也承认:DeepSeek视为开源创新的“催化剂”,强调其高效、低耗的架构正推动成本骤降,打破了传统算力竞赛模式。
-
资本市场和技术媒体纷纷关注这一突破:德银报告、券商调研以及科技投资者纷纷预言,DeepSeek的开源策略将重新洗牌“百模大战”,推动行业从众多原型竞争走向极少数技术领先者独占鳌头的新局面。
的确,在国内反映更加猛烈。云服务巨头纷纷入局,华为云、阿里云、腾讯云、百度智能云、京东云、联通云等,或是联合推出服务,或是实现零代码部署,或是限时免费体验。开发平台也不甘落后,OpenRouter、秘塔 AI 搜索等积极接入。企业应用更是遍地开花,从视觉中国用于图像语义分析,到小米优化终端交互体验,再到纵览新闻提升讯息服务,DeepSeek R1 的影响力迅速蔓延。
最近半个月扑面而来的消息,感觉都和DeepSeek有关系:



设想一下,像阿里、百度、腾讯、讯飞等大厂都是投入巨资开发自己的大模型,现在不得不部署DeepSeek v3和R1,估计它们是“打碎了牙往肚子里咽,心中苦不堪言”。
DeepSeek R1 开源构建超级生态
DeepSeek R1 以 MIT License 开源协议示人,这一决策犹如为大模型世界打开了一扇滔天洪水之门。因为在诸多开源协议中,MIT License 开源协议以其宽松性著称,支持修改、修改之后可以不开源,特别是允许任何人用于商业目的,无需支付版税或获取特别许可。企业、开发者能自由对DeepSeek R1大模型进行修改、开发插件,极大地激发了创新活力。
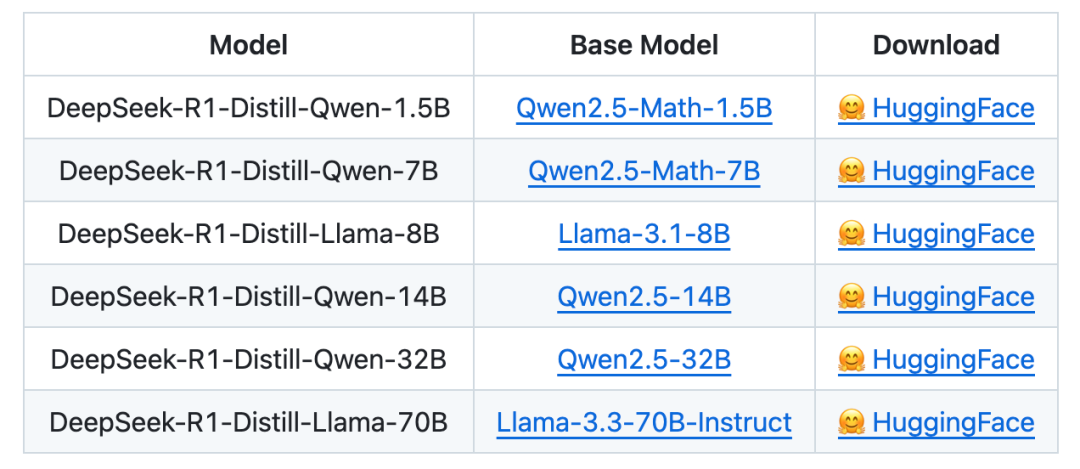
技术上,DeepSeek R1 性能好、具有很强的推理和反思能力,而且知识蒸馏技术进一步压缩模型,蒸馏出32B、14B、7B和1.5B等小模型,使其能在边缘设备上实现实时 AI 推理,像四信睿析边缘智脑网关的应用,既降低数据传输成本,又保障了数据安全。这样,DeepSeek R1多场景适配能力卓越,从云端到本地,甚至普通 CPU 都能运行,成本极低,仅为 OpenAI 同类模型的 3%,却能实现媲美 GPT - 4o 的性能。
这种开源模式迅速构建起一个庞大的生态。全球开发者踊跃参与,社区代码不断更新,漏洞快速修复。硬件厂商为满足算力需求,加速创新,提升产品性价比。商业领域新模式层出不穷,托管服务、定制插件、垂直领域微调等盈利方式如雨后春笋般涌现。

在大模型领域,“只有第一,没有第二” 的态势正愈发凸显。DeepSeek R1 凭借其开源优势,迅速抢占市场份额,吸引大量资源和关注。如今的大模型竞争,如同一场残酷的短跑竞赛,率先冲过终点线的选手才能获得最多的荣誉与资源。
从技术角度看,大模型研发需要海量数据、超强算力和顶尖算法人才。一旦有模型在某方面取得突破,如 DeepSeek R1 在成本控制和性能平衡上的卓越表现,其他模型若不能迅速跟进,就会被远远甩在身后。企业在选择接入大模型时,往往更倾向于行业内表现最优者,以获取最大的竞争优势。这就导致市场资源向头部模型高度集中,排名靠后的模型难以获得足够的发展资源,陷入恶性循环。
再者,大模型的生态构建至关重要。DeepSeek R1 开源后,吸引了全球开发者共建生态,形成了强大的网络效应。新进入者或排名靠后的模型,要想打破这种生态壁垒,需要付出巨大的努力,且成功概率极低。
与此同时,开源赋能正在推动技术体系的深度融合与生态重构。开源不仅打破了以往封闭研发的壁垒,更催生了一个跨学科、跨企业的信息共享平台,使得技术进步由少数巨头垄断转变为全体参与者协同共进。技术上,基于深度学习的链式思维(Chain-of-Thought)、简化参数蒸馏、混合专家(MoE)和多头隐层注意力(MLA)等机制正成为各家模型竞相攻克的关键难题;生态层面,开放的代码、透明的算法验证流程以及标准化的接口,促使硬件算力、软件优化和场景应用形成了良性互动。例如,云服务平台已针对DeepSeek系列模型提供一键部署与差异化加速方案,这不仅降低了应用门槛,也使得各大模型能更灵活地嵌入企业级应用,从金融风控到智能制造,无不显现出生态重构带来的应用创新。另外,跨领域数据协同、共享训练资源、以及基于反馈的持续迭代,都为模型适应复杂多变场景提供了技术支撑。
DeepSeek通过开源透明、成本大幅下降的优势,迫使原有“百模”参与者不得不重新审视自身定位、不得不在成本控管、实用场景和算法创新上加快迭代步伐。面对 DeepSeek R1 带来的巨大冲击,国内大模型并非毫无机会,但破局之路充满挑战。例如,差异化发展是关键。国内大模型应结合自身优势,挖掘细分领域需求。例如,在特定行业数据丰富的情况下,开发针对性强的行业大模型,像金融、医疗等领域,通过提供更精准、专业的服务,避开与通用大模型的正面竞争。例如:
-
通义千问:阿里云在云服务市场占据领先地位,通义千问可以借助其强大的云计算资源和广泛的客户基础,快速推广和应用,例如,为阿里云的企业客户提供定制化的大模型解决方案,助力企业在智能客服、智能营销等领域实现创新。同时,阿里达摩院在人工智能领域有深厚的技术积累,不断推动通义千问在模型架构、训练算法等方面的创新。如通过优化 “MoE+Transformer” 混合架构,提升模型的性能和效率,使其在处理复杂任务时表现更出色。
-
豆包:字节跳动拥有庞大的产品矩阵,如抖音、今日头条等,豆包可以与这些产品深度融合,实现多场景覆盖。以抖音为例,豆包不断提升多模态生成能力,如优化视频生成模型,可以为抖音的创作者提供智能创作助手,帮助他们生成优质的视频内容,提高创作效率。
-
Kimi 将强化学习作为重点发展方向,通过让 AI 根据自己的生成数据进行学习,不断优化奖励模型,争取在处理复杂任务和自适应学习方面取得突破。而且Kimi一直在教育领域发力,可以进一步专注教育领域应用大模型,开发基于 Kimi 的智能教育产品,如智能辅导系统、数学学习软件等,为学生提供个性化的学习服务。
-
MinMax:在多模态领域有深入的研究和发展,将继续把多模态做好,实现无限长的输入和输出,并降低错误率。其次,在海外市场加大力度拓展,因为其开放平台已在 20 个国家实现业务落地,C 端产品触达超 180 个国家和地区。
-
智谱:在基础模型的预训练和效果提升方面有深入的研究和实践,基础不错,有一定的潜力。例如,其发布的 Step 系列大模型矩阵覆盖了从千亿参数到万亿参数、从语言到多模态、从理解到生成的全方位能力。这次DeepSeek对它的刺激估计也很大,会不会卧薪尝胆,咱们拭目以待。
-
文心一言:虽然百度之前的策略是“All inAI”,文心一言也是最早推出来的,但结果不够理想,现在感觉落后了。如果调查一下,除了DeepSeek,大家用豆包、Kimi的机会更多。但是,“大模型+联网搜索”已经成为标准配置,百度在搜索引擎领域占据主导地位,拥有海量的用户数据和强大的计算资源。文心一言可以借助这些优势,让“联网搜索”效果更佳,同时进行大规模的数据训练和模型优化,提升模型能力,也许还能赶上来。
-
面壁小钢炮:专注于端侧 AI 的商业化布局,在性能、能耗和速度上有一点优势。其端侧模型 “面壁小钢炮 MiniCPM” 支持将长文本与超清图像处理结合,还引入了实时视频理解功能,适用于多种智能终端设备。我们前面也提到DeepSeek蒸馏出32B、14B、7B和1.5B等小模型,对面壁智能带来极大挑战,面壁智能必须进一步加强与华为、英特尔等行业巨头展开深入合作,布局消费电子、AI 手机和智能家居等智能终端。通过与硬件厂商的合作,将端侧 AI 技术融入到更多的智能产品中,推动智能化升级。
-
星火大模型:科大讯飞在人工智能领域有长期的技术积累,不断对星火大模型进行升级和优化,但模型的表现还不够惊艳。不过,讯飞在教育、医疗、能源、汽车、家电、机器人等应用市场有优势,并通过与各行业的头部企业合作,深入了解行业需求,开发出更贴合实际应用场景的解决方案。未来,讯飞可能还是发力“语音智能和大模型”的融合,加强其应用产品的开发。
信息来源:软件工程3.0时代


